PocketFlow
PocketFlow is an open-source framework for compressing and accelerating deep learning models with minimal human effort. Deep learning is widely used in various areas, such as computer vision, speech recognition, and natural language translation. However, deep learning models are often computational expensive, which limits further applications on mobile devices with limited computational resources.
PocketFlow aims at providing an easy-to-use toolkit for developers to improve the inference efficiency with little or no performance degradation. Developers only needs to specify the desired compression and/or acceleration ratios and then PocketFlow will automatically choose proper hyper-parameters to generate a highly efficient compressed model for deployment.
Framework
The proposed framework mainly consists of two categories of algorithm components, i.e. learners and hyper-parameter optimizers, as depicted in the figure below. Given an uncompressed original model, the learner module generates a candidate compressed model using some randomly chosen hyper-parameter combination. The candidate model's accuracy and computation efficiency is then evaluated and used by hyper-parameter optimizer module as the feedback signal to determine the next hyper-parameter combination to be explored by the learner module. After a few iterations, the best one of all the candidate models is output as the final compressed model.
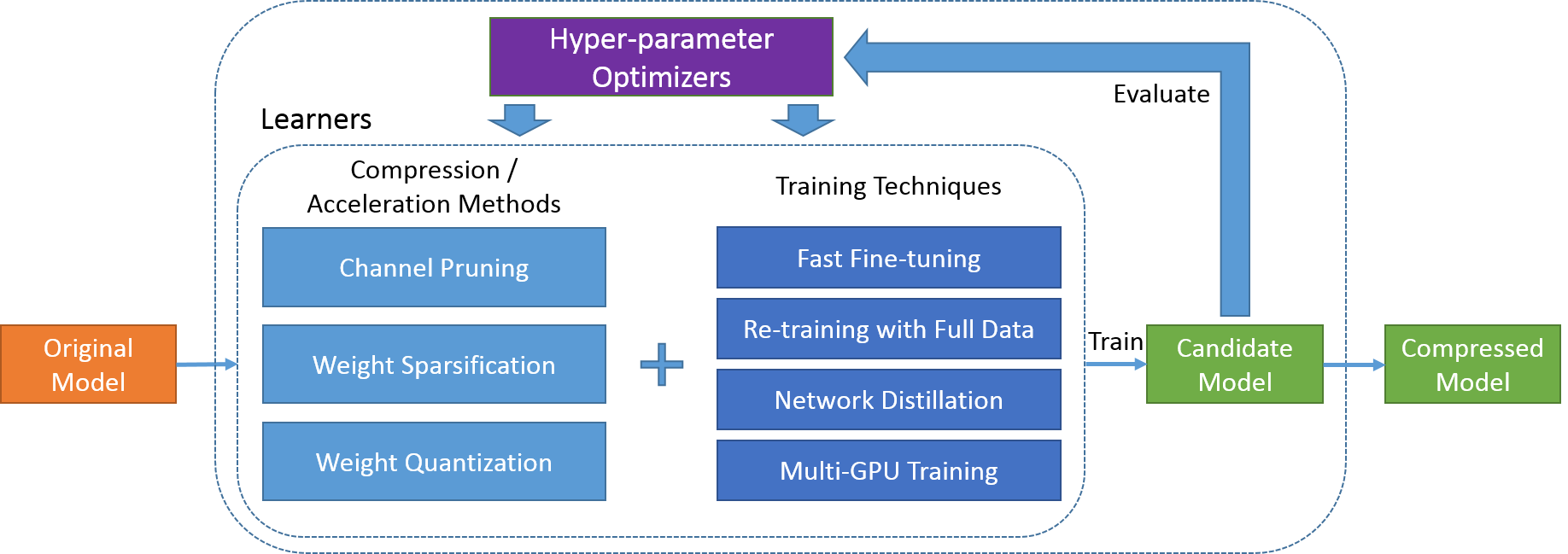
Learners
A learner refers to some model compression algorithm augmented with several training techniques as shown in the figure above. Below is a list of model compression algorithms supported in PocketFlow:
| Name | Description |
|---|---|
ChannelPrunedLearner |
channel pruning with LASSO-based channel selection (He et al., 2017) |
DisChnPrunedLearner |
discrimination-aware channel pruning (Zhuang et al., 2018) |
WeightSparseLearner |
weight sparsification with dynamic pruning schedule (Zhu & Gupta, 2017) |
UniformQuantLearner |
weight quantization with uniform reconstruction levels (Jacob et al., 2018) |
UniformQuantTFLearner |
weight quantization with uniform reconstruction levels and TensorFlow APIs |
NonUniformQuantLearner |
weight quantization with non-uniform reconstruction levels (Han et al., 2016) |
All the above model compression algorithms can trained with fast fine-tuning, which is to directly derive a compressed model from the original one by applying either pruning masks or quantization functions. The resulting model can be fine-tuned with a few iterations to recover the accuracy to some extent. Alternatively, the compressed model can be re-trained with the full training data, which leads to higher accuracy but usually takes longer to complete.
To further reduce the compressed model's performance degradation, we adopt network distillation to augment its training process with an extra loss term, using the original uncompressed model's outputs as soft labels. Additionally, multi-GPU distributed training is enabled for all learners to speed-up the time-consuming training process.
Hyper-parameter Optimizers
For model compression algorithms, there are several hyper-parameters that may have a large impact on the final compressed model's performance. It can be quite difficult to manually determine proper values for these hyper-parameters, especially for developers that are not very familiar with algorithm details. Recently, several AutoML systems, e.g. Cloud AutoML from Google, have been developed to train high-quality machine learning models with minimal human effort. Particularly, the AMC algorithm (He et al., 2018) presents promising results for adopting reinforcement learning for automated model compression with channel pruning and fine-grained pruning.
In PocketFlow, we introduce the hyper-parameter optimizer module to iteratively search for the optimal hyper-parameter setting. We provide several implementations of hyper-parameter optimizer, based on models including Gaussian Processes (GP, Mockus, 1975), Tree-structured Parzen Estimator (TPE, Bergstra et al., 2013), and Deterministic Deep Policy Gradients (DDPG, Lillicrap et al., 2016). The hyper-parameter setting is optimized through an iterative process. In each iteration, the hyper-parameter optimizer chooses a combination of hyper-parameter values, and the learner generates a candidate model with fast fast-tuning. The candidate model is evaluated to calculate the reward of the current hyper-parameter setting. After that, the hyper-parameter optimizer updates its model to improve its estimation on the hyper-parameter space. Finally, when the best candidate model (and corresponding hyper-parameter setting) is selected after some iterations, this model can be re-trained with full data to further reduce the performance loss.
Performance
In this section, we present some of our results for applying various model compression methods for ResNet and MobileNet models on the ImageNet classification task, including channel pruning, weight sparsification, and uniform quantization. For complete evaluation results, please refer to here.
Channel Pruning
We adopt the DDPG algorithm as the RL agent to find the optimal layer-wise pruning ratios, and use group fine-tuning to further improve the compressed model's accuracy:
| Model | FLOPs | Uniform | RL-based | RL-based + Group Fine-tuning |
|---|---|---|---|---|
| MobileNet-v1 | 50% | 66.5% | 67.8% (+1.3%) | 67.9% (+1.4%) |
| MobileNet-v1 | 40% | 66.2% | 66.9% (+0.7%) | 67.0% (+0.8%) |
| MobileNet-v1 | 30% | 64.4% | 64.5% (+0.1%) | 64.8% (+0.4%) |
| Mobilenet-v1 | 20% | 61.4% | 61.4% (+0.0%) | 62.2% (+0.8%) |
Weight Sparsification
Comparing with the original algorithm (Zhu & Gupta, 2017) which uses the same sparsity for all layers, we incorporate the DDPG algorithm to iteratively search for the optimal sparsity of each layer, which leads to the increased accuracy:
| Model | Sparsity | (Zhu & Gupta, 2017) | RL-based |
|---|---|---|---|
| MobileNet-v1 | 50% | 69.5% | 70.5% (+1.0%) |
| MobileNet-v1 | 75% | 67.7% | 68.5% (+0.8%) |
| MobileNet-v1 | 90% | 61.8% | 63.4% (+1.6%) |
| MobileNet-v1 | 95% | 53.6% | 56.8% (+3.2%) |
Uniform Quantization
We show that models with 32-bit floating-point number weights can be safely quantized into their 8-bit counterpart without accuracy loss (sometimes even better!). The resulting model can be deployed on mobile devices for faster inference (Device: XiaoMi 8 with a Snapdragon 845 CPU):
| Model | Acc. (32-bit) | Acc. (8-bit) | Time (32-bit) | Time (8-bit) |
|---|---|---|---|---|
| MobileNet-v1 | 70.89% | 71.29% (+0.40%) | 124.53 | 56.12 (2.22\times) |
| MobileNet-v2 | 71.84% | 72.26% (+0.42%) | 120.59 | 49.04 (2.46\times) |
- All the reported time are in milliseconds.