Uniform Quantization
Introduction
Uniform quantization is widely used for model compression and acceleration. Originally the weights in the network are represented by 32-bit floating-point numbers. With uniform quantization, low-precision (e.g. 4-bit or 8-bit) fixed-point numbers are used to approximate the full-precision network. For k-bit quantization, the memory saving can be up to 32 / k. For example, 8-bit quantization can reduce the network size by 4 folds with negligible drop of performance.
Currently, PocketFlow supports two types of uniform quantization learners:
-
UniformQuantLearner: a self-developed learner for uniform quantization. The learner is carefully optimized with various extensions and variations supported. -
UniformQuantTFLearner: a wrapper based on TensorFlow's quantization-aware training training APIs. For now, this wrapper only supports 8-bit quantization, which leads to approximately 4x memory reduction and 3x inference speed-up.
A comparison of these two learners are shown below:
| Features | UniformQuantLearner |
UniformQuantTFLearner |
|---|---|---|
| Compression | Yes | Yes |
| Acceleration | Yes | |
| Fine-tuning | Yes | |
| Bucketing | Yes | |
| Hyper-param Optimization | Yes |
Algorithm
Training Workflow
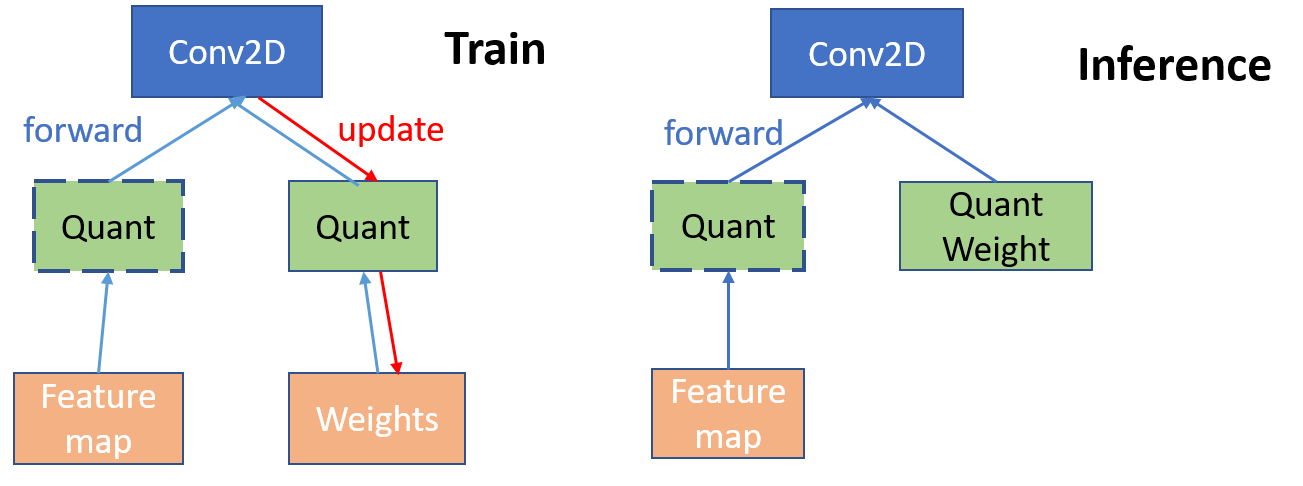
Both two uniform quantization learners generally follow the training workflow below:
Given a pre-defined full-precision model, the learner inserts quantization nodes and operations into the computation graph of the model. With activation quantization enabled, quantization nodes will also be placed after activation operations (e.g. ReLU).
In the training phase, both full-precision and quantized weights are kept. In the forward pass, quantized weights are obtained by applying the quantization function on full-precision weights. To update full-precision weights in the backward pass, since gradients w.r.t. quantized weights are zeros almost everywhere, we use the straight-through estimator (STE, Bengio et al., 2015) to pass gradients of quantized weights directly to full-precision weights for update.
Quantization Function
Uniform quantization distributes all the quantization points evenly across the range \left[ w_{min}, w_{max} \right], where w_{max} and w_{min} are the maximum and minimum values of weights in each layer (or bucket). The original full-precision weights are then assigned to their closest quantization points. To achieve this, we first normalize the full-precision weights x to \left[ 0, 1 \right]:
where \alpha = w_{max} - w_{min} and \beta = w_{min}. Then, we assign \text{sc} \left( x \right) to its closest quantization point (assuming k-bit quantization is used):
and finally we use inverse linear transformation to recover the quantized weights to the original scale:
UniformQuantLearner
UniformQuantLearner is a self-developed learner, which allows a number of customized configurations for uniform quantization. For example, the learner supports bucketing, leading to more fine-grained quantization and better performance. The learner also allows to allocate different bits across layers, in which users can turn on the hyper-parameter optimizer with reinforcement learning to search for the optimal bit allocation strategy.
Hyper-parameters
To configure UniformQuantLearner, users can pass options via the TensorFlow flag interface. The available options are listed as follows:
| Option | Description |
|---|---|
uql_weight_bits |
the number of bits for weights. Default: 4. |
uql_activation_bits |
the number of bits for activation. Default: 32. |
uql_save_quant_model_path |
quantized model's save path. Default: ./uql_quant_models/model.ckpt |
uql_use_buckets |
the switch to use bucketing. Default: False. |
uql_bucket_type |
two bucket type available: [split, channel]. Default: channel. |
uql_bucket_size |
the number of bucket size for bucket type split. Default: 256. |
uql_quantize_all_layers |
the switch to quantize first and last layers of network. Default: False. |
uql_quant_epoch |
the number of epochs for fine-tuning. Default: 60. |
uql_enbl_rl_agent |
the switch to enable RL to learn optimal bit strategy. Default:False. |
Here, we provide detailed description (and some analysis) for above hyper-parameters:
uql_weight_bits: The number of bits for weight quantization. Generally, 8 bit does not hurt the model performance while it can compress the model size by 4 folds. While 2 bit and 4 bit could lead to drop of performance on large datasets such as Imagenet.uql_activation_bits: The number of bits for activation quantization. When both weights and activations are quantized, 8 bit does not lead to apparent drop of performance, and sometimes can even increase the classification accuracy, which is probably due to better generalization ability. Nevertheless, the performance will be more challenged when both weights and activations are quantized to lower bits, comparing to weight-only quantization.uql_save_quant_mode_path: the path to save the quantized model. Quantization nodes have already been inserted into the graph.uql_use_buckets: the switch to turn on the bucket. With bucketing, weights are split into multiple pieces, while the \alpha and \beta are calculated individually for each piece. Therefore, turning on the bucketing can lead to more fine-grained quantization.uql_bucket_type: the type of bucketing. Currently two types are supported: [split,channel].splitrefers to that the weights of a layer are first concatenated into a long vector, and then cut it into pieces according touql_bucket_size. The remaining last piece will be padded and taken as a new piece. After quantization of each piece, the vectors are then folded back to the original shape as the quantized weights.channelrefers to that weights with shape[k, k, cin, cout]in a convolutional layer are cut intocoutbuckets, where each bucket has the size ofk * k * cin. For weights with shape[m, n]in fully connected layers, they are cut intonbuckets, each of sizem. In practice, bucketing with typechannelcan be calculated more efficiently comparing to typesplitsince there are less buckets and less computation to iterate through all of them.uql_bucket_size: the size of buckets when using bucket typesplit. Generally, smaller bucket size can lead to more fine grained quantization, while more storage are required since full precision statistics (\alpha and \beta) of each bucket need to be kept.uql_quantize_all_layers: the switch to quantize the first and last layers. The first and last layers of the network are connected directly with the input and output, and are arguably more sensitive to quantization. Keeping them un-quantized can slightly increase the performance, nevertheless, if you want to accelerate the inference speed, all layers are supposed to be quantized.uql_quant_epoch: the epochs for fine-tuning a quantized network.uql_enbl_rl_agent: the switch to turn on the RL agent as hyper parameter optimizer. Details about the RL agent and its configurations are described below.
Configure the RL Agent
Once the hyper parameter optimizer is turned on, i.e., uql_enbl_rl_agent==True , the RL agent will automatically search for the optimal bit allocation strategy for each layer. In order to search efficiently, the agent need to be configured properly. While here we list all the configurable hyper parameters for the agent, users can just keep the default value for most parameters, while modify only a few of them if necessary.
| Option | Description |
|---|---|
uql_equivalent_bits |
the number of re-allocated bits that is equivalent to uniform allocation of bits. Default: 4. |
uql_nb_rlouts |
the number of roll outs for training the RL agent. Default: 200. |
uql_w_bit_min |
the minimal number of bits for each layer. Default: 2. |
uql_w_bit_max |
the maximal number of bits for each layer. Default: 8. |
uql_enbl_rl_global_tune |
the switch to fine-tune all layers of the network. Default: True. |
uql_enbl_rl_layerwise_tune |
the switch to fine-tune the network layer by layer. Default: False. |
uql_tune_layerwise_steps |
the number of steps for layer-wise fine-tuning. Default: 300. |
uql_tune_global_steps |
the number of steps for global fine-tuning. Default: 2000. |
uql_tune_disp_steps |
the display steps to show the fine-tuning progress. Default: 100. |
uql_enbl_random_layers |
the switch to randomly permute layers during RL agent training. Default: True. |
Detailed description and usages for above hyper-parameters are listed below:
uql_equivalent_bits: the total number of bits used in the optimal strategy will not exceed n_{param}*uql_equivalent_bits. For example, by settinguql_equivalent_bits=4, the RL agent will try to find the best quantization strategy with the same compression ratio to that each layer is quantized by 4 bits.
The following parameters can be kept in default value in most cases. Users can also modify them when using their customized models if necessary.
uql_nb_rlouts: the number of roll-out for training the RL agent. Generally we will use the first quarter ofuql_nb_rloutsfor collection of the training buffer, and last three quarters for the training of the agent. The larger theuql_nb_rlouts, the slower the search for the hyper-parameter optimizer.uql_w_bit_min: the minimum number of quantization bit for a layer. This is used to constrain the searching space and avoid extreme strategies that crash the entire performance of the compressed model.uql_w_bit_max: the maximum number of quantization bit for a layer. This is used to constrain the searching space and avoid that one layer may use too much unnecessary bits.uql_enbl_rl_global_tune: the switch to globally fine-tune the network in each roll-out, which is done by updating the full-precision weights for all layers via the STE estimator. The aim of the fine-tune is to obtain effective reward from the current strategy.uql_enbl_rl_layerwise_tune: the switch to layer-wise fine-tune the network in each roll-out, which is done by minimizing the l2-norm between the quantized layer and full-precision layer.uql_tune_layerwise_steps: the number of steps for layer-wise fine-tuning. Generally, the larger the value, the more precise the reward and thereon the better the strategy.uql_tune_global_steps: the number of steps for global fine-tuning. Generally, the larger the value, the more precise the reward and thereon the better the strategy.uql_tune_disp_steps: the intervals to display the global training process in each roll-out.uql_enbl_random_layers: the switch to randomly permute layers of the network when searching the optimal strategy. This could be helpful since the bit budget used in previous layers may affect the searching space for following layers, while randomly shuffling all layers makes sure that all layers have equal probability of all strategies.
Usage Examples
In this section, we provide some usage examples to demonstrate how to use UniformQuantLearnerunder different execution modes and hyper-parameter combinations.
To quantize the network, users should first get the model prepared. Users can either use the pre-built models in PocketFlow, or develop their customized nets following the model definition in PocketFlow (for example, resnet_at_cifar10.py). Once the model is built, the quantization can be easily triggered by directly as follows:
To quantize a ResNet-20 model for CIFAR-10 classification task with 4 bits in the local mode, use:
# quantize resnet-20 on CIFAR-10
sh ./scripts/run_local.sh nets/resnet_at_cifar10_run.py \
--learner=uniform \
--uql_weight_bits=4 \
--uql_activation_bits=4 \
To quantize a ResNet-18 model for ILSVRC_12 classification task with 8 bits in the docker mode with 4 GPUs, and allow to use the channel-wise bucketing, use:
# quantize the resnet-18 on ILSVRC-12
sh ./scripts/run_docker.sh nets/resnet_at_ilsvrc12_run.py \
-n=4 \
--learner=uniform \
--uql_weight_bits=8 \
--uql_activation_bits=8 \
--uql_use_buckets=True \
--uql_bucket_type=channel
To quantize a MobileNet-v1 model for ILSVRC_12 classification task with 4 bits in the seven mode with 8 GPUs, and allow the RL agent to search for the optimal bit strategy, use:
# quantize mobilenet-v1 on ILSVRC-12
sh ./scripts/run_seven.sh nets/mobilenet_at_ilsvrc12_run.py \
-n=8 \
--learner=uniform \
--uql_enbl_rl_agent=True \
--uql_equivalent_bits=4 \
UniformQuantTFLearner
PocketFlow also wraps the quantization aware training in TensorFlow. The quantized model can be directly exported to .tflite format via export_quant_tflite_model.py in PocketFlow, and then be easily deployed on Android devices.
To configure UniformQuantTFLearner, the hyper-parameters are as follows:
| Option | Description |
|---|---|
uqtf_save_path |
UQ-TF: model\'s save path. Default: ./models_uqtf/model.ckpt. |
uqtf_save_path_eval |
UQ-TF: model\'s save path for evaluation. Default: ./models_uqtf_eval/model.ckpt. |
uqtf_weight_bits |
UQ-TF: # of bits for weight quantization. Default: 8. |
uqtf_activation_bits |
UQ-TF: # of bits for activation quantization. Default: 8. |
uqtf_quant_delay |
UQ-TF: # of steps after which weights and activations are quantized. Default: 0. |
uqtf_freeze_bn_delay |
UT-TF: # of steps after which moving mean and variance are frozen. Default: None. |
uqtf_lrn_rate_dcy |
UQ-TF: learning rate\'s decaying factor. Default: 1e-2. |
Here, the detailed description (and some analysis) for some above hyper-parameters are listed as follows:
uqtf_quant_delay: The number of steps to start fine-tuning on the quantized network. Before the training step reachesuqtf_quant_delay, only full precision weights of the model are updated.uqtf_freeze_bn_delay: The number of steps after which the moving mean and variance of batch normalization layers are frozen and used, instead of the batch statistics during training.uqtf_lrn_rate_dcy: The decay of learning rate for the quantized model. Generally the quantized network needs smaller learning rate comparing to that for the full-precision model.
Usage Examples
To deploy a quantized network on Android devices, there are generally 3 steps:
Quantize the pre-trained network
To quantize a MobileNet-v1 model for ILSVRC-12 classification task with 8 bits in the seven mode, use:
# quantize MobileNet-v1 on ILSVRC-12
$ ./scripts/run_seven.sh nets/mobilenet_at_ilsvrc12_run.py -n=8 \
--learner uniform-tf \
--nb_epochs_rat 0.2
where --nb_epochs_rat 0.2 specifies that only 20% training epochs to be used, which usually should be enough.
Export to .tflite format
# load the checkpoints in ./models_uqtf_eval
$ python export_quant_tflite_models.py \
--model_dir ./models_uqtf_eval \
--enbl_post_quant
Note that we enable the enbl_post_quant option to ensure all operations being quantized. On one hand, some operations may not be successfully quantized via TensorFlow's quantization-aware training APIs, so post-training quantization can help remedy this, possibly at the cost of slightly reduced accuracy of the quantized model. On the other hand, users can directly export a full-precision model to its quantized counterpart without going through the UniformQuantTFLearner. This could be helpful when users want to quickly evaluate the inference speed, or there is more tolerance for the performance degradation of quantized model.
If the conversion completes without error, then .pb and .tflite files will be saved in ./models_uqtf_eval.
Deploy on Mobile Devices
The Deployment of a quantized model is very similar to that of a full-precision model, as is shown in the tutorial page. Specifically, users need to do the following modifications:
- In ImageClassifierQuantizedMobileNet.java L24: rename the class w.r.t. your model.
- In ImageClassifierQuantizedMobileNet.java L46: replace the model input "mobilenet_quant_v1_224.tflite" to your "*.tflite" file.
-
In ImageClassifierQuantizedMobileNet.java L51: replace the label file "labels_mobilenet_quant_v1_224.txt" to your label files.
-
In Camera2BasicFragment.java L332: change the name of the class accordingly.